Big Data
| Typ | Vorlesung mit integrierter Übung |
| Dozent | H. Martin Bücker, Johannes Schoder, Robert Josef Domogalla |
| Credit points | 6 ECTS = 4 SWS |
| Nächste Möglichkeit | WS 2026/2027 |
| Friedolin | Search in Friedolin |
Beschreibung
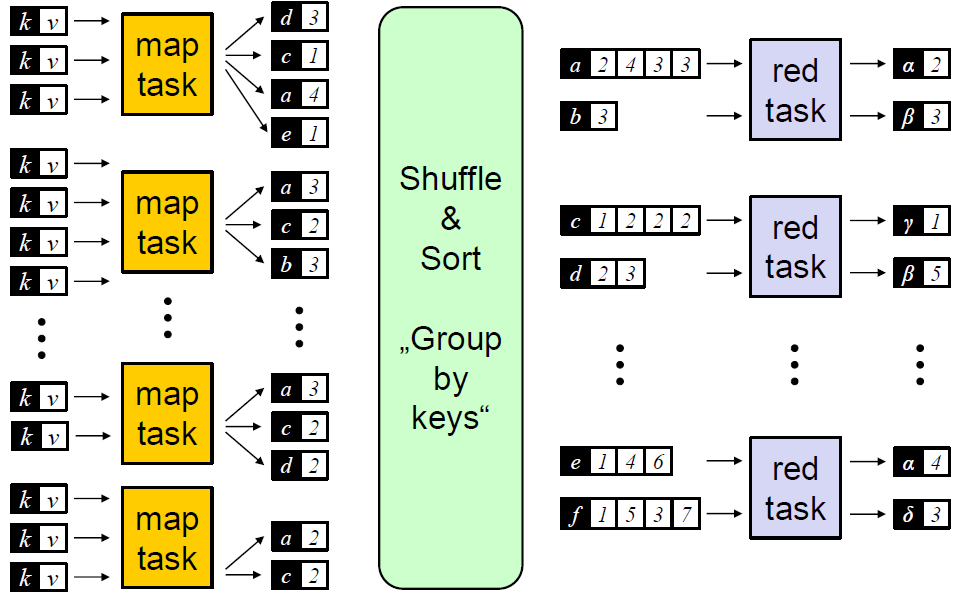
Das Thema "Big Data" ist nicht erst seit der Diskussion um die systematische Erfassung von personenbezogenen Daten aus allen Lebensbereichen durch internationale Nachrichtendienste und global operierenden Internet-Firmen in aller Munde. Die Analyse von großen und heterogenen Datenmengen etabliert sich in der modernen Wissensgesellschaft zunehmend als eine der methodischen Kernkompetenzen von Informatik und Mathematik. Ziel dieser Lehrveranstaltung sind jedoch nicht die zugrundeliegenden Methoden der Datenanalyse, sondern der praktische Umgang mit Systemen, mit denen solche Analysen heute durchgeführt werden. Insbesondere werden die parallelen Programmiermodelle MapReduce und Spark vorgestellt und in praktischen Übungen vertiefend behandelt. Ziel der Lehrveranstaltung ist neben dem Erlernen der Programmierung solcher Big-Data-Systeme vor allem die Fähigkeit, die versteckten Performance-Engpässe von solchen Programmen erkennen zu können und durch geeignete Mittel umgehen zu können.
Studiengänge
Diese einführende Vorlesung ist geeignet für Studierende zu Beginn des Masterstudiums, kann aber auch am Ende eines Bachelorstudiums gehört werden. Kenntnisse in serieller Programmierung werden vorausgesetzt. Dagegen sind Kenntnisse in traditionellen parallelen Programmiermodellen (MPI, OpenMP, CUDA) nicht notwendig und auch nicht wirklich hilfreich.
| M.Sc. Computational and Data Science | Pflichtbereich |
| M.Sc. Informatik (V2016) | Wahlpflichtbereich Informatik und Vertiefung Informatik |
| M.Sc. Informatik (V2021) | High-Performance Computing I-V (6 LP) |
Die Veranstaltung ist auch geeignet für Studierende aus Mathematik und anderen naturwissenschaftlichen Fachrichtungen.